

.webp)
The right talent is always harder to find, faster to lose, and more expensive to replace. Yet, most enterprise talent acquisition (TA) teams respond with more sourcing channels, more outbound campaigns, and more tools, rather than focusing on sourcing and retaining the best talent.
The more concerning issue is that sourcing is still treated as a set of activities. A LinkedIn campaign here, a cold outreach sequence there, a job board contract somewhere else, with no architecture connecting them.
None of the tactics compound, and the function ends each quarter with the same shortage of qualified candidates the moment a requisition opens.
Traditional talent sourcing strategies were built for a sequential, application-driven, requisition-bound model.
However, hiring today is continuous, relationship-driven, and capacity-bound, with AI tools entering the stack on a quarterly cadence and digital workers taking on parts of execution that human recruiters used to own.
In this blog, we will examine where traditional candidate sourcing breaks against modern hiring, the four layers of a system-based sourcing architecture, and how Asymbl approaches sourcing as part of workforce orchestration rather than a standalone function
What Traditional Sourcing Strategies Get Right (And Why They Worked)
The recruiting playbooks every talent acquisition team learned, post the role, run the campaign, work the channel, did real work for the model of hiring they were built on.
The discipline of mapping channels to roles, of standardizing outreach cadence, and of tracking source-of-hire reliably came from these strategies.
1. Sourcing In An Application-Driven Hiring Model
Traditional sourcing strategies were designed within an application-driven hiring model. The job was posted, candidates applied, recruiters worked the inbound flow, and sourcing existed primarily to compensate for inbound shortages.
When the post produced enough applicants, sourcing was a supplementary motion. When inbound thinned out, sourcing leaned harder on outbound, referrals, and channel expansion until the volume returned.
The model worked because most candidates moved when they decided to apply. The recruiter did not need a continuous relationship with the candidate. The candidate showed intent through the application, and the funnel began at that point.
Sourcing was the activity that filled the top of the funnel when applications fell short, and the metric set, source-of-hire, channel performance, applications per requisition, was scoped to that boundary.
2. Why Channel-Based Strategies Were Effective In A Linear Funnel
The recruiting funnel was linear. Awareness produced applicants, applicants converted to qualified candidates, qualified candidates converted to interviews, and interviews converted to hires. Each stage handed off to the next in roughly the same order, and the metrics described that order with precision.
Channel-based strategies fit the linearity. A LinkedIn campaign produced applicants at one cost, while a job board listing produced applicants at another.
Each channel had a known yield, a known cost, and a known quality profile, and the function could allocate budget across channels based on which one produced the best applicants for which kind of role.
The optimization motion was clear. Test channels, measure yield, double down on the channels that produced quality applicants for the cost, and prune the channels that did not.
The function had a recognizable pattern. Every quarter, source-of-hire reports surfaced, which channels carried the function, the budget shifted accordingly, and the next quarter ran on a refined channel mix.
Inside a linear funnel, that motion produced predictable improvement, and the playbook compounded year over year.
3. The Recruiter As The Primary Execution Engine
In the traditional model, the recruiter was the execution engine. Sourcing tools surfaced candidates, channels produced inbound flow, and the recruiter worked every relationship that resulted.
However, outreach was written by hand, and screening was conducted by phone. The system relied on human output at the candidate level.
It worked because the volume was tractable. A recruiter handling 15 to 25 open requisitions could realistically maintain the relationships those roles required. The strategies were calibrated to that capacity, and the playbook gave recruiters a reasonable shot at filling their roles within the cycle the business expected.
Sourcing was hard work, and the work was within reach for an experienced recruiter operating with a focused channel mix.
The recruiter's judgment also held the system together. Boolean search produced long candidate lists, and the recruiter's instinct narrowed the list to the candidates worth contacting.
Outbound messages varied based on the recruiter's read of the candidate, and follow-ups paced themselves to the recruiter's sense of when a candidate was warming up.
The strategy was channel-driven on paper, but recruiter-driven in practice. The recruiter-driven playbook produced repeatable results, and the breakdown only became visible when the operating environment changed.
Where Candidate Sourcing Breaks In Modern Hiring
The misalignment between how hiring used to work and how it works now shows up in every direction the modern function tries to expand:
Four structural breakdowns show up consistently across enterprise recruiting workflows running on the standard sourcing playbook.
1. Requisition-Based Sourcing Resets Context Every Time
Traditional sourcing strategies assume the requisition is the start of the work. The role opens, the recruiter writes the Boolean string, runs the search, drafts the outreach sequence, and works the campaign until the role fills.
The role closes, the campaign archives, and the next requisition begins the cycle again with a clean slate.
The reset is expensive because every candidate engaged for a prior role disappears from the active workspace when the role closes.
The recruiter who built rapport with a passive candidate during a six-month nurture loses access to that relationship the moment the requisition resolves. The sourcing context, who responded, who declined, who showed interest in adjacent roles, sits archived behind a closed requisition that nobody re-opens.
For example, a passive candidate who was not interested in March often becomes interested in October when their situation changes. The requisition-based model treats each of these as cold leads that have to be reacquired, paid for again, and re-engaged from scratch.
The institutional memory, the function should be compounding instead of dispersing with every closed requisition. Recruiters spend their cycles recreating relationships that the function already had.
The cost compounds quietly because no metric makes it visible as every requisition starts at zero. The function pays full sourcing cost on a candidate it has already paid to source, screen, and engage, sometimes multiple times across multiple roles.
2. Candidate Data Fractures Across CRM, ATS, And Outreach Tools
Modern sourcing runs across multiple systems.
- Engagement campaigns live in the candidate relationship management (CRM) tool.
- Application records live in the applicant tracking system (ATS).
- Outbound sequences live in a sourcing platform.
- Job board responses land in another inbox.
- LinkedIn InMails sit in a separate workflow.
This fragmentation breaks every part of the sourcing strategy that depends on context. A recruiter cannot tell whether a candidate they are about to cold-message has already engaged with three campaigns this year.
The candidate gets contacted multiple times by multiple workflows, often inconsistently, and the function looks disorganized to the candidate without realizing it.
The data fragmentation also limits what AI can do. AI sourcing tools depend on context to surface meaningful matches. When the context lives across five systems, and none of them share signal natively, the AI tool sees only the slice of the candidate that lives inside its own silo.
Reactivating the prior pipeline becomes nearly impossible at scale with this data quality and fragmentation. The candidates exist in the system, somewhere, and finding them requires searching across tools that do not share a primary key.
3. Channel Expansion Without Coordination Creates Noise, Not Signal
The standard response to a weak pipeline is more channels. Add LinkedIn Recruiter, then add a niche job board, then add an outbound sequence, then add an employee referral platform.
Each addition makes sense in isolation. As the channel mix expands, the function feels more capable, and the pipeline looks busier, but the hiring outcomes do not improve in proportion.
The reason is that channel expansion without coordination produces noise rather than a signal. Every channel adds another stream of candidates. Every stream needs its own configuration, outreach cadence, tracking, and reporting view.
Recruiters end up reconciling output across channels manually, copying candidates between systems, and reading the same candidate in three different tools without realizing it is the same person.
The coordination problem also shows up at the candidate level. The same candidate gets contacted by an InMail campaign, a separate cold email sequence, and an automated outreach from the sourcing tool within the same week.
Each touchpoint is internally polite, but the aggregate experience is incoherent. The candidate hears from the organization three times in three voices, with no record of the prior contact informing the next one. Strong candidates filter the organization out faster as the noise increases.
Tool layering compounds the cognitive load on recruiters. With each new channel, recruiters switch between more interfaces, learn more vendor workflows, and spend more time stitching outputs together into a coherent candidate view.
The intent of every new tool is simplification, but the aggregate effect is fragmentation. The function ends up running more channels with less clarity about what each one is producing, and the marginal value of the next channel addition keeps declining.
4. Human Capacity Becomes The Limiting Factor
Traditional sourcing strategies assume the recruiter can carry the relationship work. Outreach is written individually, and screening is conducted by phone. The model relies on human output at the candidate level, and the volume the recruiter can sustain is the cap on what sourcing can produce.
At enterprise scale, that cap is binding. A recruiter can personalize 30 outreach messages a day, phone-screen 8 to 12 candidates, and sustain meaningful relationships with maybe 200 active passive candidates before quality drops.
The aggregate sourcing capacity of a team is the sum of these caps across recruiters, and that sum has not changed materially in a decade, even as enterprise hiring volume has.
Adding more channels does not lift the cap because the bottleneck is downstream. The new channel adds candidates to a recruiter who was already at capacity, and the additional volume gets handled at lower quality, slower cadence, or not at all.
The function looks busier without producing more output. The strategies designed for human output hit a ceiling that more activity does not penetrate.
Hiring growth on the business side does not slow down because the recruiting function has run out of capacity. Roles are still open, and targets still exist. The function either delivers or escalates.
The escalation path, agency partners, contingent workers, expedited campaigns, run at premium cost, lower quality, and worse downstream outcomes than the function would produce internally if it had the capacity.
The constraint is structural, and the standard sourcing playbook has no answer to it because the playbook was designed within the constraint.
Rethinking Candidate Sourcing: From Channels To Continuous Pipelines
The shift in recruiting needs is structural, not tactical, because sourcing can no longer be tied to the moment a job opening exists or organized around the channel mix that produces inbound for it.
The function has to operate sourcing as a continuous system that runs whether or not a specific requisition is open, that maintains relationships with candidates whose connection to the company extends beyond any one role, and that produces qualified, engaged talent on the cadence the business actually hires.
Candidates exist in the organization's ecosystem long before and long after any single role. A passive candidate engaged today may not be ready for two years, or a finalist who declined this quarter may accept the next adjacent role.
None of these relationships fit inside a requisition window, and none of them produce value if the architecture treats the requisition as the unit of work.
The functions that win the next decade will treat sourcing as always-on pipelines. Pipelines that:
- Run continuously
- Segment talent by skill family and engagement readiness,
- Surface qualified candidates the moment a requisition opens
- Compound institutional memory across every cycle.
The sourcing strategy stops being a list of tactics and becomes the design of a system. The metrics shift from channel performance to pipeline coverage, while the operating model shifts from recruiter-as-execution-engine to recruiter-as-orchestrator of human and digital teammates working the same pipeline.
Rebuilding Candidate Sourcing Strategies As A System
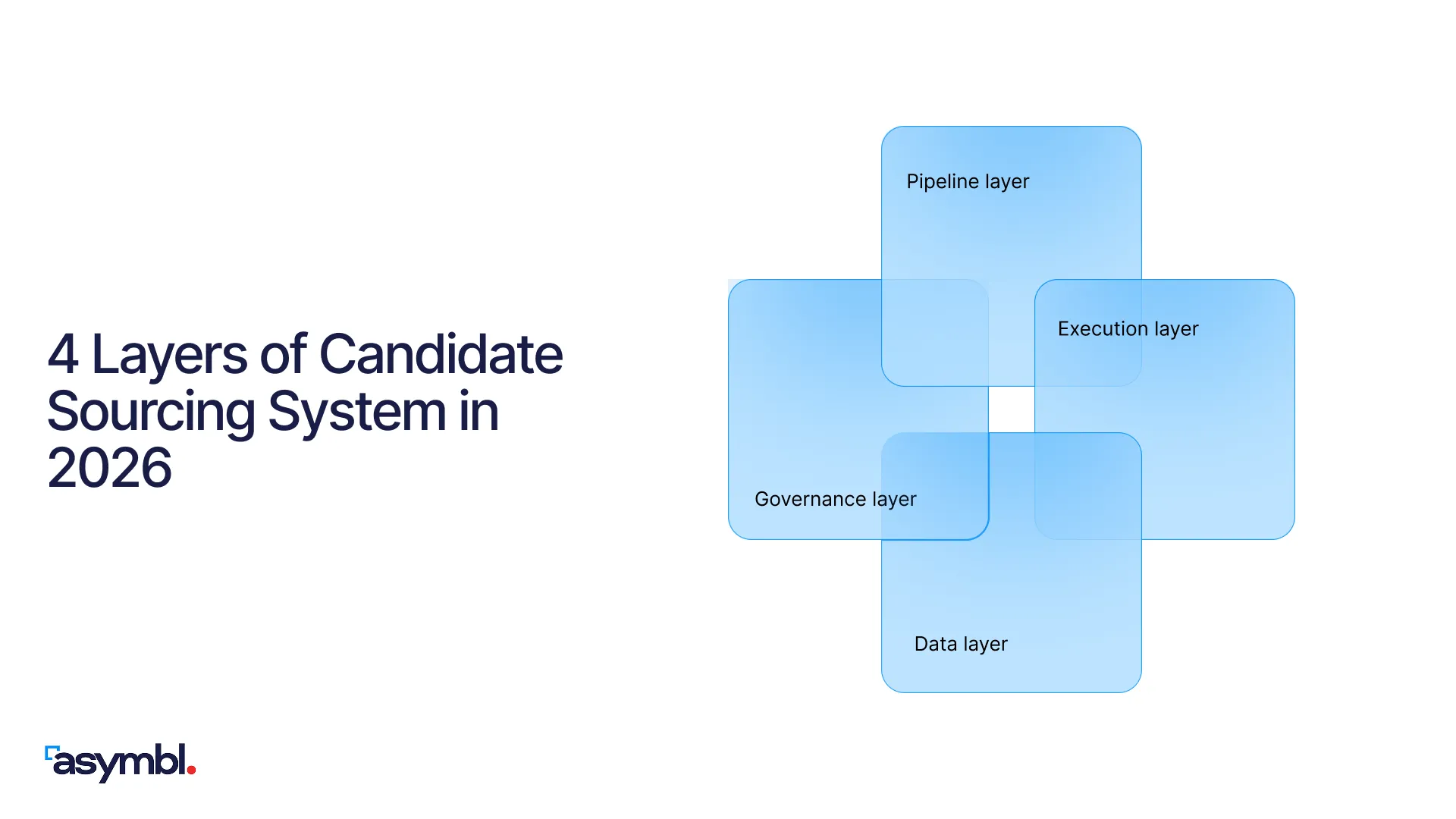
A continuous sourcing system has four layers:
- Pipeline layer
- Execution layer
- Data layer
- Governance layer
Each layer has a defined purpose, owner, and relationship with the layers above and below it. Together, the four layers describe what modern candidate sourcing strategies actually look like when they operate as a system rather than a stack of tactics.
1. Pipeline Layer
The pipeline layer is the persistent inventory of candidates the function maintains, independent of any specific requisition.
Talent pools are organized around the skill families the business hires for, with segmentation that reflects how the function actually engages candidates over time. The segmentation matters because not every candidate in the pipeline is at the same stage of readiness, and the engagement strategy varies sharply by stage.
Skill segmentation maps the pipeline to the work the business produces. Engineering pools, sales pools, operations pools, and leadership pools all need to be tracked separately because the sourcing motion, the channel mix, the engagement cadence, and the conversion economics differ across them.
A pipeline structured by skill family lets the function plan capacity against the demand patterns each family produces, rather than reporting an aggregate that hides where the gaps actually sit.
Engagement segmentation tracks where each candidate is in the relationship, and each segment carries a different engagement strategy, conversion rate, and cost-to-fill profile. Treating them the same is what makes the standard sourcing playbook expensive.
Readiness segmentation tracks how close each candidate is to a hire. For example, candidates who are open to moving in the next 30 days or in the next 6 to 12 months.
The readiness signal informs which candidates the function prioritizes for active outreach versus longer-cycle nurture, and the signal has to be refreshed continuously because candidate situations change.
A pipeline layer designed around persistent talent pools, segmented across these three dimensions, produces a different operating standard than a sourcing playbook organized around channels.
2. Execution Layer
The execution layer runs the sourcing motions against the pipeline.
- Inbound campaigns capture candidates who fill out the application directly.
- Outbound sequences engage passive candidates that the firm targets actively.
Each motion runs in parallel, against the same pipeline, with the same data foundation underneath, and the orchestration layer routes work between human recruiters and digital workers based on what each contributor does best.
Inbound motions handle the candidates who come to the organization through job posts, employer brand campaigns, employee referrals, and direct applications, all of which flow into the pipeline through structured intake.
The execution layer captures the inbound flow, scores it against open and anticipated requisitions, and routes qualified candidates into active engagement while moving lower-fit candidates into longer-cycle nurture.
Outbound motions engage the passive candidates the company targets. Sourcing AI, recruiter outreach, and digital worker outreach all operate against the same target list, with the orchestration layer ensuring that no candidate gets multiple uncoordinated touches in the same week.
Outbound runs continuously rather than in requisition-bound bursts, with sequencing, follow-up, and re-engagement handled inside one system that sees the full candidate record. The execution feels coherent to the candidate because it is coherent in the architecture.
3. Data Layer
Every layer above the data layer depends on the data foundation being unified. The candidate is one entity in the system, with a single primary record, with every event in the candidate's history attached to that record.
Engagement campaigns from the marketing function, application records from sourcing, outbound sequences, interview outcomes, hire decisions, and post-hire performance all aggregate against the same candidate, with no parallel records, no synced duplicates, and no fragments held in separate tools.
Without the unified record, the pipeline layer cannot produce reliable segmentation, the execution layer cannot route work intelligently, and the governance layer cannot enforce ownership.
Every modern sourcing capability is downstream of the data foundation, and the function that has not unified its data cannot operate any of those capabilities at scale.
4. Governance Layer
The governance layer defines who owns what inside the sourcing system, how candidates get scored, and how prioritization decisions get made when capacity has to be allocated.
Without governance, the layers above run on default behavior, which usually means the loudest voice in the room wins the next sourcing campaign, and the function operates reactively against whichever requisition escalated most recently.
Ownership has to be explicit at the role level. For example:
- Pipeline coverage might be owned by a Director of Sourcing for each skill family.
- Engagement campaigns might be owned by a Sourcing Operations lead.
Each owner has the authority to influence the inputs that move their metric and the accountability for the output.
Scoring rules define how candidates get prioritized. Fit against active and anticipated requisitions, engagement readiness, prior interaction history, and likelihood of acceptance all feed a structured score that the system uses to decide which candidates get worked first.
The scoring has to be transparent enough that the function can audit it, adjustable enough that the function can refine it, and consistent enough that two recruiters reading the same candidate record draw the same conclusion.
Prioritization rules govern how capacity gets allocated when demand exceeds supply:
- Which requisitions get worked first when sourcing capacity is tight?
- Which candidates get human recruiter time when digital workers cannot resolve them?
- Which job families get pipeline investment when the budget is finite?
The rules have to exist before the conflict happens, because the moment of conflict is the worst time to decide them. A governance layer that defines prioritization in advance produces a function that operates predictably under load. A function without governance escalates every conflict to a leader who has to make the call on the fly.
Architectural Requirements For Modern Candidate Sourcing
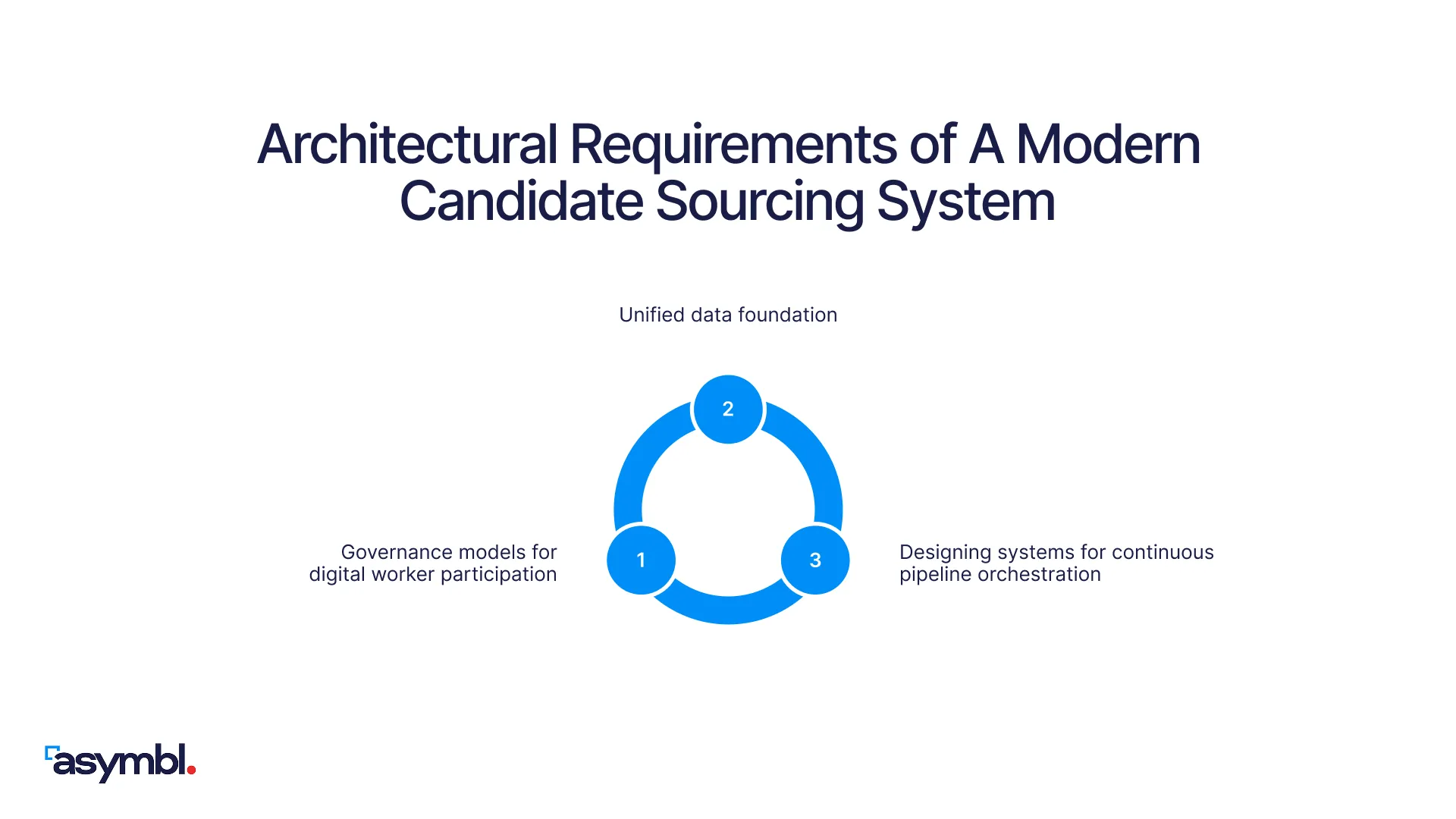
Four architectural properties make continuous, system-based sourcing possible. Together, they describe what the underlying system has to look like for the sourcing strategy to operate as designed.
1. Unified Data Foundation
Every modern sourcing capability depends on data that follows the candidate across the full lifecycle. Engagement, application, outbound, screening, interview, offer, hire, and post-hire signal all need to live in a model where they connect to the same talent record.
Without a unified data foundation, every sourcing motion is calculated against a partial view, every AI tool sees only its slice of the candidate, and every metric carries the same gaps the architecture introduced.
The unification cannot be added on top of an integration project because integrations move data between systems and leave the systems separate. Two integrated systems still hold two versions of the truth, with the sync introducing latency and conflict that the workflow has to handle.
The unification has to happen at the data model level, where the candidate, the requisition, the engagement history, the prior interview outcomes, the hire decision, and the post-hire performance all share the same primary record.
Asymbl Digital Recruiter is Salesforce-based, which means the candidate, requisition, engagement, hire, and downstream business records all live in the same data model. There is no ATS-to-CRM sync, no middleware, no parallel data store.
Pipeline coverage, rediscovery scoring, and full-lifecycle candidate context can be calculated end-to-end because the data does not break across systems.
2. Governance Models For Digital Worker Participation
Digital workers handling parts of sourcing execution have to be governed the same way human recruiters are governed, but most are not.
They are deployed as tools, measured anecdotally, and left to operate without defined responsibilities or performance accountability. This drift often goes undetected, and the output quality varies. The function absorbs the variance because no governance is wired to surface it.
According to the 2025 McKinsey State of AI Report, 88% of organizations report regular AI use in at least one business function, and the same data shows that organizations capturing meaningful enterprise-level value remain a small minority.
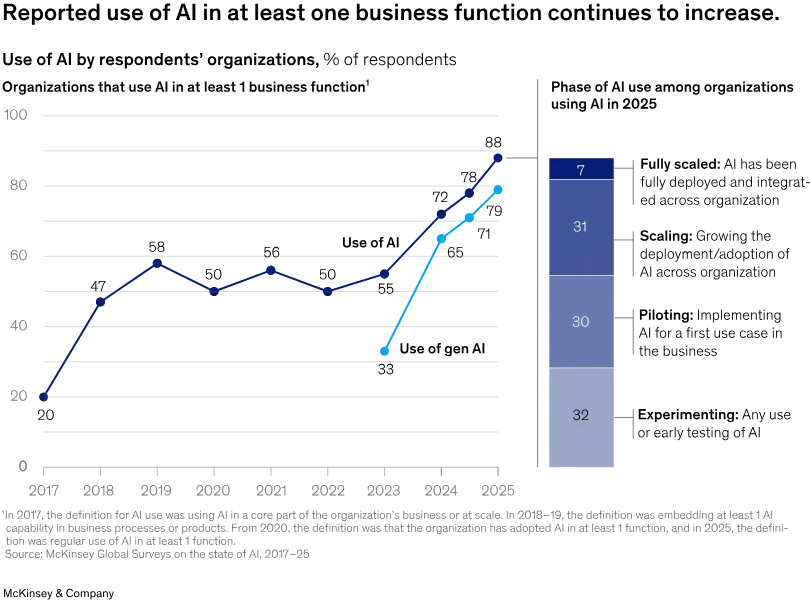
The gap between deployment and value is overwhelmingly a governance problem. Digital workers running without defined responsibilities, performance metrics, and accountable managers produce output that nobody is structured to evaluate or improve.
A governance model for digital workers in sourcing assigns each digital worker a defined role, KPIs, an accountable manager, and a coaching cadence. The digital worker handling:
- Outbound personalization has performance metrics tied to response rate, candidate quality, and message coherence with the rest of the engagement track.
- Rediscovery has metrics tied to surfaced candidate fit and conversion against active requisitions.
Without these definitions, digital labor floats outside the operating model, and nobody is accountable for its contribution.
3. Designing Systems For Continuous Pipeline Orchestration
Continuous pipeline orchestration requires a layer that runs sourcing motions against persistent pipelines, routes work between human and digital teammates, and adjusts in real time based on signals from the data layer.
The orchestration layer is what turns a sourcing system into a sourcing engine. Without it, the pipeline, execution, data, and governance layers exist as components that do not coordinate, and the function has to coordinate them manually.
Orchestration also makes pipeline signals actionable. When pipeline coverage drops below a threshold for a skill family, the orchestration layer routes additional sourcing capacity to that family before the gap escalates into a hiring crisis. The signal does not wait for a quarterly review. It acts against the operating model in real time.
Asymbl Talent Intelligence is the layer that powers this orchestration on the platform. It captures the judgment, context, and pattern recognition that accumulates across every workflow and decision, and makes that signal available to every digital worker and every human teammate.
Predicted pipeline depth, shortfalls, and reactivation candidates become continuous outputs that the system produces from the underlying data, and the sourcing strategy operates against that signal natively.
How Asymbl Embodies This Shift
Asymbl operates sourcing as one motion inside a unified workforce orchestration platform built on Salesforce. The pipeline, execution, data, and governance layers run on the same foundation, with human and digital workers operating against the same candidate record, the same workflow engine, and the same governance framework from day one
1. Designing Sourcing As Part Of Workforce Orchestration
Asymbl is a Salesforce-based workforce orchestration platform. Sourcing inside the platform is not a discrete tool with its own data model, workflows, and metric set.
It is one of several connected motions that share the same candidate record, execution layer, and governance framework as the rest of the recruiting function. The candidate engaged through a sourcing motion enters the same pipeline as the candidate who applied directly.
The data captured at sourcing flows continuously into screening, interviewing, and post-hire performance.
The design philosophy starts with the operating model and works backward to the technology. The function defines what work needs to get done, who or what does each piece of work, how the work hands off between human and digital teammates, and how each contributor is measured.
Most recruiting platforms invert this. The platform exists, the function adapts its sourcing strategies to what the platform supports, and the strategies describe what the platform happens to enable rather than what the function actually wants to operate.
Asymbl is built to invert that inversion. It supports the operating model that the function designs. Sourcing operates as one connected motion inside that operating model, with the same architectural rigor as every other motion the function runs.
2. Unifying Data
The CRM-based architecture gives Asymbl a unified data foundation by design. The candidate, the requisition, the engagement history, and the prior interview outcomes all live in the same Salesforce data model.
There is no ATS-to-CRM sync, no middleware, no parallel data store. The candidate exists once in the system, with every event in the candidate's history attached to the same record.
The unified foundation makes pipeline operations work the way the strategy describes.
- Pipeline coverage gets calculated against a single canonical count of qualified candidates.
- Rediscovery surfaces silver medalists and prior pipeline in seconds rather than days.
The function operates against one truth, which is what continuous sourcing requires to function at scale.
Digital Recruiter, and Talent Intelligence operate inside this unified architecture, with Talent Intelligence as the learning layer underneath.
Talent Intelligence scores candidates against jobs and jobs against candidate profiles using AI fit analysis, surfaces top talent across available, in-contact, and prior placement pools, and returns a structured breakdown of why a candidate fits a role.
The pipeline layer becomes searchable, scorable, and actionable in the same workflow the recruiter already operates against.
3. Embedding Digital Workers Into Sourcing Operations
Asymbl Digital Recruiter carries a job description, performance metrics, escalation logic, and a manager from the day it goes live. The agent runs candidate outreach at scale, screens responses against role criteria, and feeds qualified candidates into the active pipeline.
Its contribution to every sourcing event is recorded in the same data model that the human team operates against.
A function with five recruiters and three digital workers reports its sourcing output the same way a function with eight recruiters does, in the units the business cares about.
Candidates engaged, candidates qualified, pipeline depth produced, and hires delivered all aggregate across human and digital labor because the architecture treats both as participants in the same operating model.
Conclusion
Strategies built for an application-driven, requisition-bound, recruiter-as-execution-engine model run inside a hiring environment that no longer matches any of those assumptions, and the gap is what hollow pipelines, missed plans, and rising sourcing costs actually reflect.
The functions that will lead the next decade are the ones that move beyond tactic-by-tactic sourcing and design systems where pipeline, execution, data, and governance operate together.
- Continuous pipelines replace requisition-bound campaigns.
- Unified candidate records replace fragmented system silos.
- Hybrid human and digital execution replaces the recruiter-as-bottleneck.
Asymbl helps enterprise hiring teams move from sourcing as activities to sourcing as a system. Book a demo with Asymbl to see how continuous sourcing operates in practice, calibrated to your hiring volume and operating model.
Reading Time to Fill: From Speed Score to Capacity Map
Break time to fill into stages to find the slow one, separate internal delay from your time to fill benchmark, and orchestrate capacity.

The Right Fit Starts With a Conversation.
See what working together could look like.
.webp)